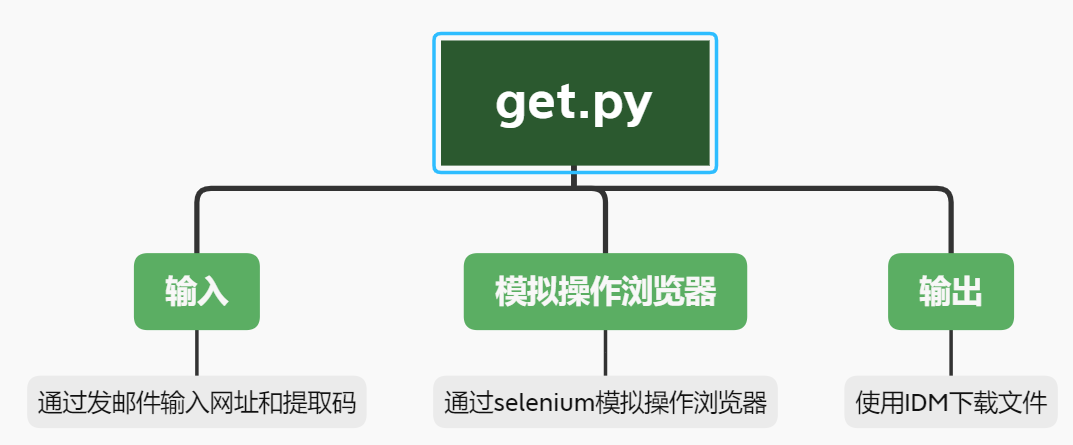
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
| import email
import keyring
paswd = keyring.get_password('163', '***@163.com')
import email.header
import imaplib
from bs4 import BeautifulSoup
class IMAP:
def __init__(self):
# self.user_id = 'XXXX@qq.com' # QQ邮箱地址
# self.password = 'password ' # 邮箱密码(现在基本都是第三方客户端授权码)
# self.imap_server = 'imap.qq.com'
self.user_id = '***@163.com' # 163邮箱地址
self.password = paswd
self.imap_server = 'imap.163.com'
def login(self):
try:
serv = imaplib.IMAP4_SSL(self.imap_server, 993) # SSL加密
print('imap4 服务器连接成功')
except Exception as e:
print('imap4 服务器连接失败:', e)
exit(1)
try:
serv.login(self.user_id, self.password)
print('imap4 登录成功')
return serv
except Exception as e:
print('imap4 登录失败:', e)
exit(1)
def loginout(self, conn):
"""
登出邮件服务器
:param conn: imap连接
:return:
"""
conn.close
conn.logout()
def get_content(self, conn):
"""
获取指定邮件,解析内容
:param conn: imap连接
:return:
"""
# 在连接服务器后,搜索之前,需要选择邮箱,默认select(mailbox='INBOX', readonly=False)
conn.select()
# 筛选符合条件的邮件,这里不知道怎么过滤复杂条件,只能过滤未读邮件或全部
# ret, data = conn.search(None, 'UNSEEN') # 未读邮件
# ret, data = conn.search(None, '(FROM "***@qq.com")')
ret, data = conn.search(None, 'ALL') # 所有邮件
# 邮件列表
email_list = data[0].split()
if len(email_list) == 0:
print('收件箱为空,已退出')
exit(1)
# 获取最后一封邮件的序号
item = email_list[len(email_list) - 1]
# 获取最后一封邮件内容
ret, data = conn.fetch(item, '(RFC822)')
msg = email.message_from_string(data[0][1].decode('gbk'))
sub = msg.get('subject')
email_from = msg.get('from')
email_to = msg.get('to')
sub_text = email.header.decode_header(sub)
email_from_text = email.header.decode_header(email_from)
email_to_text = email.header.decode_header(email_to)
# 如果是特殊字符,元组的第二位会给出编码格式,需要转码
if sub_text[0]:
global sub_detail
sub_detail = self.tuple_to_str(sub_text[0])
email_from_detail = ''
for i in range(len(email_from_text)):
email_from_detail = email_from_detail + self.tuple_to_str(email_from_text[i])
email_to_detail = ''
for i in range(len(email_to_text)):
email_to_detail = email_to_detail + self.tuple_to_str(email_to_text[i])
print('主题:', sub_detail)
print('发件人:', email_from_detail)
print('收件人:', email_to_detail)
# 通过walk可以遍历出所有的内容
for part in msg.walk():
# 这里要判断是否是multipart,如果是,数据没用丢弃
if not part.is_multipart():
# 字符集
# charset = part.get_charset()
# print('charset: ', charset)
# 内容类型
content_type = part.get_content_type()
# print('content-type', content_type)
# 如果是附件,这里就会取出附件的文件名,以下两种方式都可以获取
# name = part.get_param("name")
name = part.get_filename()
if name:
# 附件
# 中文名获取到的是=?GBK?Q?=D6=D0=CE=C4=C3=FB.docx?=(中文名.docx)格式,需要将其解码为bytes格式
trans_name = email.header.decode_header(name)
if trans_name[0][1]:
# 将bytes格式转为可读格式
file_name = trans_name[0][0].decode(trans_name[0][1])
else:
file_name = trans_name[0][0]
print('开始下载附件:', file_name)
attach_data = part.get_payload(decode=True) # 解码出附件数据,然后存储到文件中
try:
f = open(file_name, 'wb') # 注意一定要用wb来打开文件,因为附件一般都是二进制文件
except Exception as e:
print(e)
f = open('tmp', 'wb')
f.write(attach_data)
f.close()
print('附件下载成功:', file_name)
else:
# 文本内容
txt = part.get_payload(decode=True) # 解码文本内容
# 分别解释text/html和text/plain两种类型,纯文本解释起来较简单,两种类型内容一致
if content_type == 'text/html':
# print('以下是邮件正文(text/html):')
# 这里笔者不同邮件服务器遇到了不同情况,只解释了QQ邮箱,163的可以修改代码:
# QQ邮箱
# 1、有两层
# 标签,格式为
#文 本1
#文本2
# 2、只有一层
#标签,格式为
#文本1
#文本2
# 163邮箱
# 只有一层
#标签,格式为
#文本1
#文本2
soup = BeautifulSoup(str(txt, 'gbk'), 'lxml')
div_data = soup.find_all('div')
if len(div_data) > 1:
for each in div_data[1:]:
print(each.text)
else:
for each in soup.find_all('p'):
print(each.text)
elif content_type == 'text/plain':
# print('以下是邮件正文(text/plain):')
# 纯文本格式为bytes,不同邮件服务器较统一
print(str(txt, 'gbk'))
def front(self, conn):
"""
使用163邮箱,必须在select之前上传客户端身份信息,否则报错:command SEARCH illegal in state AUTH, only allowed in states SELECTED
:param conn: imap连接
:return:
"""
imaplib.Commands['ID'] = 'AUTH'
# 如果使用163邮箱,需要上传客户端身份信息
args = ("name", "XXXX", "contact", "XXXX@163.com", "version", "1.0.0", "vendor", "myclient")
typ, dat = conn._simple_command('ID', '("' + '" "'.join(args) + '")')
# print(conn._untagged_response(typ, dat, 'ID'))
def tuple_to_str(self, tuple_):
"""
元组转为字符串输出
:param tuple_: 转换前的元组,QQ邮箱格式为(b'\xcd\xf5\xd4\xc6', 'gbk')或者(b' ', None),163邮箱格式为('', None)
:return: 转换后的字符串
"""
if tuple_[1]:
out_str = tuple_[0].decode(tuple_[1])
else:
if isinstance(tuple_[0], bytes):
out_str = tuple_[0].decode('gbk')
else:
out_str = tuple_[0]
return out_str
'''
if __name__ == '__main__':
IMAP = IMAP()
conn = IMAP.login()
IMAP.front(conn)
IMAP.get_content(conn)
IMAP.loginout(conn)
URL=sub_detail
'''
IMAP = IMAP()
conn = IMAP.login()
IMAP.front(conn)
IMAP.get_content(conn)
IMAP.loginout(conn)
URL=sub_detail
# 为方便调用这里赋值给URL,URL是你发送的主题
|